
本稿はJCB Advent Calendar 2022の12月24日の記事です。
JCBデジタルソリューション開発部 PFチームの平松です。
前回の私の記事にて、クレジットカード会社のシステムのリモート運用がなぜ難しいかについて解説いたしました。
今回は、Kubernetes運用で重要な要素である cordon / drain 操作をリモートで行えるようにした件についてご紹介していきたいと思います。 (前提として、Kubernetesについてある程度の知識を有していることを想定して記載しています。)
cordon / drain 操作について
まずはこれらのコマンドについて簡単に解説していきます。 ポイントとしてはKubernetesのコンピュートリソースであるノードに異常が発生した場合に、速やかに実行すべき操作となります。1
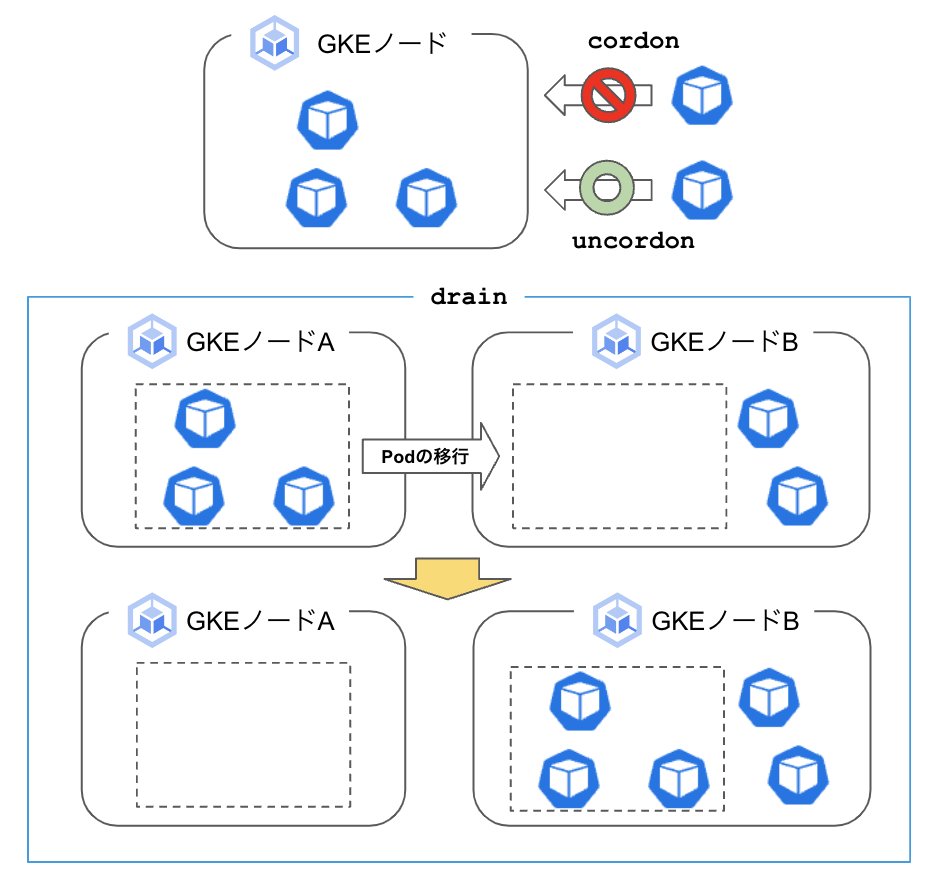
cordon
選択したノードに新たにPodが起動できないようにする操作。ノードに対して異常が起こった際に実施し、異常なノード上にアプリが展開されて被害が拡大することを防ぐ。解除するにはuncordon操作する。drain
選択したノードで起動しているPodを別のノードへ退去させる操作。cordon後に速やかに実行し、異常が発生したノードで処理が行われることを防ぐ。
リモートでのコマンド実行
上記の通り、Kubernetes上のノードに異常が発生した場合はcordon / drainコマンドを速やかに実行して被害の拡大を防ぐことが求められます。 このため、これらのコマンドをリモートで実行できるように以下の通り構築いたしました。
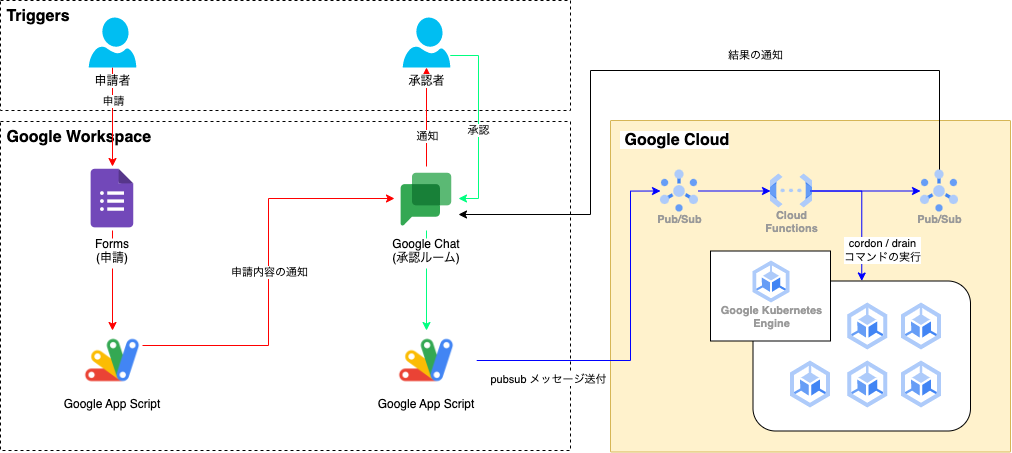
なお、構築したPub/Sub及びCloud Functionsの実行権限についてはサービスアカウントによる制御を厳密に行っており、予期せぬ実行は発生しないよう安全に配慮した作りとなっています。
本構成の実際の操作の流れについて以下に示します。
- 専用Google Formにて、ターゲットとなるノードと操作(cordon / drain / uncordon)を選択し、申請する。
- 申請内容をGoogle App Script(以降GAS)を用いてGoogle Chatに通知し、承認者が申請を確認し、承認する。
- 承認されたらGAS経由でCloud Pub/Subにメッセージを送付する。
- Cloud Pub/SubからCloud Functionsを呼び出し、対象の操作をGoogle Kubernetes Engineに対して実行する。
- 動作結果をCloud Pub/Sub経由でGoogle Chatに通知する。
drain時のワンポイント
実際にオンデマンド業務を運用する際、drain操作によってノード移行を実施する際は以下の点に注意が必要です。
- 安全なPodの停止
- バッチジョブの扱い
安全なPodの停止
Kubernetes上にリリースするアプリケーションは、drainに限らずクラスタオートスケーラーのスケールイン時など、いつPodの停止処理が実行されても業務エラーが発生しないように安全なPodの終了ができるよう設計されている必要があります。
Podの終了処理は以下の流れとなります。
- ユーザが Pod を削除するコマンド (
kubectl delete) を送信する。デフォルトの猶予期間(Grace Period) は30秒。 - Grace Period から Pod が停止する日時が API Server の Pod に設定される。
- Pod はクライアントからリストされた際に Terminating と表示される。
- (3 と同時に) kubelet が 2 において Pod が Terminating と設定されたことが分かると、Pod のシャットダウンプロセスを開始する。
- Pod に preStop フックが定義されている場合、Pod 内でそれが呼び出される。もし preStop フックが猶予期間を過ぎてもまだ実行されている場合、直ちに次の処理に移行し猶予期間を2秒に設定する。
- Pod 内のプロセスに SIGTERM が送信される。もし猶予期間が過ぎてもまだプロセスが終了していない場合、SIGKILL が送信される。
- (3 と同時に) Service のエンドポイントのリストから Pod が削除される。
- (3 と同時に) ReplicaSets, ReplicationControllers で Pod が管理対象から削除される。
preStopの組み込み例は以下の通りです。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
spec:
template:
spec:
containers:
- name: sample-app
(略)
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 20"]
terminationGracePeriodSeconds: 30
こちらの設定値のポイントとしては、以下の通りです。
- sleep時間
オンライン処理のタイムアウト時間とServiceのエンドポイントからPodが削除される時間を合算した値を指定する。 - terminationGracePeriodSeconds
preStopのsleep時間とSIGTERM後のプロセス停止処理に必要な処理時間を合算した値を指定する。
なお、本プラットフォーム上で動作するアプリケーションについてもこの安全なPodの終了については必須の対応としており、いつPF側でdrain操作が実行されても良い仕組みについては各アプリケーションごとに検討・対応されています。
バッチジョブについて
アプリケーションの中にはバッチ処理等時間のかかるプログラムは存在します。その場合、drain操作によってPodが途中で切断されてしまうことは避けたいシチュエーションもあります。
この要件に対応するため、Kubernetes APIにてdrainを実施する際はTypes(kinds)がJobの場合を対象外とすることで、drainの対象から除外することが可能となります。 2
もちろんジョブが終了すればPodは停止するので、事前にcordonを実施しておけば次回ジョブ起動時には該当ノード上でジョブが展開されることはないため安全です。
終わりに
ここまで、Kubernetesの運用に必須となるcordon / drain 操作をリモートで行えるようにした仕組みと運用時のポイントについて記載いたしました。 運用の改善については今後も取り組んでいく課題となるので、さらなる改善を実現できた際はまたご紹介できればと思っています。
最後になりますが、JCBでは我々と一緒に働きたいという人材を募集しています。 詳しい募集要項等については採用ページをご覧下さい。
本文および図表中では、「™」、「®」を明記しておりません。
Google Cloud, GCPならびにすべてのGoogleの商標およびロゴはGoogle LLCの商標または登録商標です。
記載されているロゴ、システム名、製品名は各社及び商標権者の登録商標あるいは商標です。
- より細かい仕様の詳細は公式ドキュメントを参照してください。↩
- 参考ドキュメント : https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#types-kinds↩