
本稿はJCB Advent Calendar 2025の12月17日の記事です。
JCB デジタルソリューション開発部 アプリチームの村井です。
アプリチームではJCBが提供する様々なサービスの開発・運用をしています。
はじめに
今回はJDEPで利用しているGKE(Google Kubernetes Engine)およびその土台となる技術であるKubernetesについて、 その機能や付随するツールを使ってミッションクリティカルなアプリケーションの可用性をコストを抑制しつつ高めるTipsをまとめました。
本稿の内容はあくまでも一技術者の見解である点をご理解の上、参考になれば幸いです。
前提
本題へ入る前に2つの前提を置きます。
ミッションクリティカルなアプリケーションの定義
ミッションクリティカルと一口に言っても具備すべきシステム特性は様々ですが、本稿では以下の特性を持つアプリケーションをミッションクリティカルと定義します。
- 24/365で稼動する
- システム障害による業務影響(業務トランザクションの処理遅延、ロスト等)は許されない
コストとの両立
システム品質(本稿では可用性を対象)とそれを実現するためのコストはトレードオフです。
単純なシステムリソース拡張や、俗にいう「運用でカバー」によって品質は担保できたとしても、それらのコストが売上を上回ってしまうと事業として成立しません。
本稿ではシステムリソース/人的コストの抑制もTipsの観点に加えます。
本題
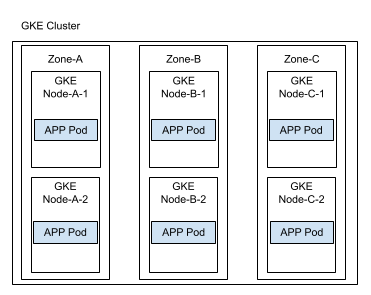
以下図のような構成のGKEクラスタを対象とします。
影響を最小限に抑えるカナリアリリース
カナリア方式のリリースとは、新しいバージョンのアプリをまずは一部のユーザだけに公開し、問題ないことを確認してから段階的に全体へ公開していくリリース方式です。
Kubernetesによるカナリア方式のリリースにはKubernetes標準のカナリアデプロイの他、Kubernetes向けのCD機能拡張ツールであるArgo Rolloutsも利用できます。
Kubernetes標準のカナリアデプロイは仕組みがシンプル(「Service」リソースおよび「Deployment」リソースで完結)です。 一方Argo Rolloutsは専用のカスタムリソース「Rollouts」を利用した高度なリリース制御が可能です。
Kubernetes標準のカナリアデプロイとArgo Rolloutsを利用したカナリアリリースにおいて、本稿で特筆すべき違いはリリース時のトラフィック制御です。
Kubernetes標準のカナリアデプロイ
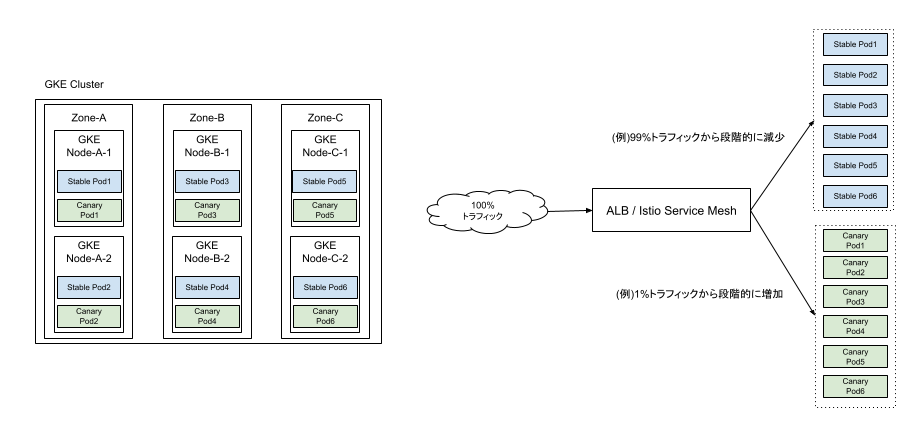
Kubernetes標準ではStableデプロイメント(=稼働中アプリモジュール)とCanaryデプロイメント(=リリース対象アプリモジュール)の合計Pod数の比率でトラフィック配分量が決まります。
仮にStableを9PodかつCanaryを1Podでカナリアデプロイする場合を考えてみると、リリース対象アプリモジュールに10%のトラフィックが流入します。
ミッションクリティカルなアプリにおいていきなり10%のトラフィックで様子を見るというのは少し不安に感じるのではないでしょうか。
では1%のトラフィックで様子を見たい場合はどうするかというと、事前にStableを99Podにスケールアウトします。
アプリモジュールの入れ替えのためにPodの数を10倍以上にすると、リリースオペレーションの工数増やKubernetesクラスタのノード数増などコストの課題が出てくる可能性があります。
Argo Rolloutsのカナリアリリース
Argo Rolloutsを利用したカナリアリリースでは、稼働中アプリモジュール(Stable)とリリース対象アプリモジュール(Canary)のPod数に依らず、総トラフィック量のパーセンテージ単位で配分を制御できます。
従って下図のようにStable:6Pod、Canary:6Podとした場合でも、Canaryに1%のトラフィックを流入させることができます。
加えて流入量を1%→50%→100%のような段階的に増加させることもでき、Kubernetes標準のカナリアデプロイよりも柔軟にトラフィック制御できます。
ただし上記のカナリアリリースを実装するにはカスタムリソース「Rollouts」の導入が必要である点と、トラフィックの制御にはALBやService Meshとの連携が必要な点でKubernetes標準よりも準備が必要です。
安定したアプリ起動を支えるLiveness/Readiness/Startup Probe
カナリア方式リリースを用いることでリリース対象アプリに何らかの不具合があった場合の業務影響を低減させることができますが、 リリース方式の実装と合わせて忘れてはいけない点が、アプリコンテナにLiveness Probe、Readiness Probe、Startup Probeを設定することです。
Liveness Probeはアプリ自体の生存確認を目的としており、処理不能判定したコンテナを再起動させることができます。
Readiness Probeはアプリが正常にリクエストを処理できる準備の完了を目的としており、新しく起動したアプリに直ぐトラフィックが流入することを防止できます。
Startup Probeはアプリが起動するまでLiveness/Readiness Probe実行の抑制を目的としており、起動の遅いアプリが意図せず再起動される事態を防止できます。
特にReadiness Probeを適切に設定しない場合、リリース対象アプリへトラフィックを配分したは良いものの、正常に処理できなかったという事態が起こり得ます。
これはカナリアリリースに限った話ではなく、Podの再配置やオートスケール時にも有効な機能です。
インフラ障害に備えたPodの分散配置
KubernetesではPodが稼働する物理的な複数のマシンをクラスタという概念で論理的に束ね、クラスタ内にアプリPodのレプリカを分散配置できます。
これにより特定のマシンが停止した場合でも他のマシンに配置されたPodで処理を継続できるため、アプリの可用性を高めることができます。
この分散配置はKubernetesによってある程度自動的に行われますが、例えば以下のようになる場合もあります。
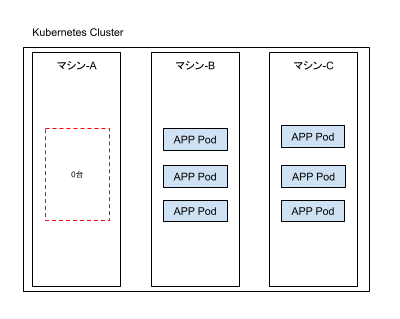
上記の例では特定のマシンに1台もPodが存在しておらず、可用性の観点から理想的なPod配置ではありません。
偏って配置されたPodを1つずつ再スケジューリングして分散させる操作も不可能では無いですが、理想状態になるまで何度も試行する運用は非現実的です。
Podの配置をより思想的な配置にする方法としてPod Topology Spread Constraintsが活用できます。
Pod Topology Spread Constraints
Pod Topology Spread Constraintsとは、ゾーンやノードの論理的なグルーピング(=トポロジ)に応じてPodの配置を均一にできる機能です。
なおこの機能自体はKubernetesの標準機能ですが、特にGKEとの相性が良いです。
GKEのクラスタを構成するノードはトポロジの指定に必要なラベルが自動付与される仕様であり、別途ラベルを付ける手間がかからないためです。
サンプルを以下に示します。
topologySpreadConstraints: # ゾーン毎のPod数の差を1個以内にする. - maxSkew: 1 topologyKey: topology.kubernetes.io/zone # GKEではtopologyKeyの指定に必要なラベルが自動付与 nodeTaintsPolicy: Honor whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: my-jdep-app matchLabelKeys: - pod-template-hash # ノード毎のPod数の差を1個以内にする. - maxSkew: 1 topologyKey: kubernetes.io/hostname # GKEではtopologyKeyの指定に必要なラベルが自動付与 nodeTaintsPolicy: Honor whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: my-jdep-app matchLabelKeys: - pod-template-hash
サンプルが有効に機能すれば、本稿の冒頭で図示したGKEクラスタイメージのようなPod配置が期待できます。
ただし、以下の点に注意する必要があります。
Pod Topology Spread Constraintsの設定のみで配置先ノードが決定される訳ではなく、他の要素(ノードの状態など)も考慮されます。よって確実に理想の分散配置になるとは限りません。
whenUnsatisfiable: DoNotScheduleと指定する場合、設定されたルールを満たさない限りPodの配置が行われなくなるため、Kubernetesによる自動的な再スケジューリングを繰り返した結果、かえって可用性の低下を招きます。
トラフィックの増加に対処するオートスケール
何らかのキャンペーンや抽選予約の開始等を契機として、流入するトラフィックが一時的に増加する状況はあり得ます。
現状のPod数でトラフィックを捌ききれない場合は、業務影響ありの障害となってしまいます。
増加するトラフィック量が判明しているならばそれを捌けるだけ事前にPod数を用意しておけば良いですが、普段発生するトラフィックを捌くには無駄が多くリソースコストの面で得策ではありません。
そこでPodのオートスケーラーを活用するとリソースを無駄なく運用できます。
HPA/VPAの特徴と課題
PodのオートスケーラーにはHPA(Horizontal Pod Autoscaler)とVPA(Vertical Pod Autoscaler)があります。
HPAはPod数のスケールアウト/スケールイン、VPAはPod自体のスケールアップ/スケールダウンを実現できます。
VPAは既存Podの一時停止が必要となるためミッションクリティカルなアプリには不向きかもしれません。
一方、HPAはPodのCPU使用率をメトリクスとしてPodを増減させるため、アプリの負荷が高まればPodを増やすというシンプルな制御が可能になります。
HPAで注意すべき点は、トラフィックの「急激な」増加にPodの追加起動が間に合うかという点です。
例えばJavaのようなJITコンパイルを採用している場合では、あらかじめダミーの処理を走らせてメモリ上にプログラムをロードしパフォーマンスを最大化するウォームアップ処理を組み込むことがあります。
ウォームアップ処理がトラフィックの急増に間に合わないと、トラフィックを捌ききれずオートスケールが意味のない対策となってしまう可能性があります。
HPAとCPU request/limitを組み合わせる
HPAによるオートスケールを意味のある対策とするために、HPAとPodに設定するCPUのrequest/limitを組み合わせた設計をします。
PodにおけるCPUのrequestとは、Podのスケジューリング時に最低限要求するCPUの値です。この要求を満たせないノードにはPodが配置されません。
一方、limitはPodが利用できるCPUの上限値です。CPUの上限を超えるとスロットリングといってアプリの処理に制限がかかります。
requestとlimitはそれぞれ任意の値を指定できます。(ただしrequest < limitです。)
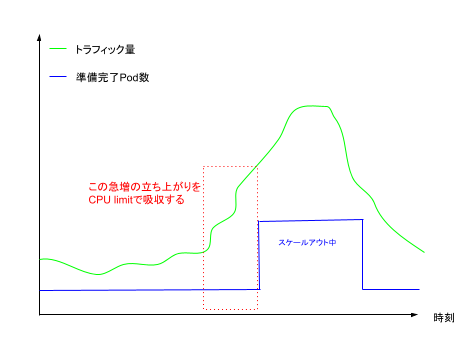
設計としては、Podの初期リソースであるrequestに対してあらかじめ余裕を持たせたlimitを設定し、オートスケールによるPod起動のリードタイムをカバーできるようにします。
大まかに以下の流れとなります。
- トラフィックの少ない平常時はスケールアウト前のPod数かつrequestに指定したCPUで処理する
- トラフィックの急増が始まったタイミングでは、HPAをトリガーすると共に、スケールアウト前のPod数かつlimitに指定したCPUで処理を吸収する
- 以降はHPAによるスケールアウト後のPod数かつrequestに指定したCPUで急増後のトラフィックを処理する
上記を実現するためには実際のトラフィックの傾向に合わせた細かなチューニングが必要になりますが、システムリソース効率と品質の両立が可能になります。
さいごに
本稿ではミッションクリティカルなアプリケーションの可用性をコストを抑制しつつ高めるTipsをまとめました。
しかしながら内容は表面的であるため、今後もアプリケーション開発を通してさらにKubernetesの知見を深めて発信できればと思います。
最後になりましたが、JCBでは我々と一緒に働きたいという人材を募集しています。
詳しい募集要項等については採用ページをご覧下さい。
本文および図表中では、「™」、「®」を明記しておりません。 Google Cloud, GCPならびにすべてのGoogleの商標およびロゴはGoogle LLCの商標または登録商標です。 記載されているロゴ、システム名、製品名は各社及び商標権者の登録商標あるいは商標です。