 本稿はJCB Advent Calendar 2024の12月25日の記事です。
本稿はJCB Advent Calendar 2024の12月25日の記事です。
デジタルソリューション開発部 SREチームの小柳津です。
JDEPでは、インシデントが発生した際に「誰がどんな役割を担い、どのように動くか」をあらかじめ明確化し、チーム全体で共通認識を持てるようにインシデントポリシーを策定しています。
今回は、その中でも SREチームのインシデントポリシー にフォーカスしてご紹介します。
JDEPにおけるインシデントポリシー
JDEPでは、すべてのサービスチームが、それぞれのサービス特性に合ったインシデントポリシーを定めています。
どこかのサービスでインシデントが発生した場合は、そのサービス担当チームがアラートを検知し、チームごとに策定している対応フローに基づいて速やかに対応しています。
SREチームにおけるインシデントポリシー
それでは本題として、SREチームのインシデントポリシー についてご紹介します。
とはいえ、インシデントに関する言葉や重要度の定義などは社内向けの情報が多いため、ここではインシデント対応時の「役割」と「対応フロー」の概要を簡単にお伝えします。
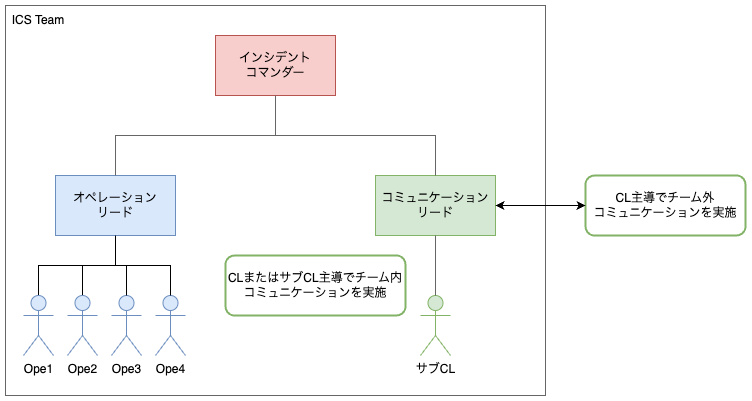
チームと役割
インシデントが発生した際は、インシデントコマンドシステム(ICS)に基づき、以下の役割を中心としたチームを組成して対応します。
※インシデントコマンドシステム(ICS)とは…
元々は災害対応などの緊急時に複数の組織が迅速かつ効率的に連携するために開発された指揮命令系統のフレームワークです。
Googleが提唱するSREの世界では、インシデント対応時に「誰がどんな判断を行い、誰が情報を集め、誰が実際の作業を担当するか」を説明するための仕組みとして応用されています。
| 役割 | 略記 | 対応内容 |
|---|---|---|
| インシデントコマンダー | IC | 障害対応の統括者。 対応方針や優先度など、重要な意思決定を担当。 |
| コミュニケーションリード | CL | 障害対応中のコミュニケーション役。 チーム内外への情報発信・情報収集を主導。 ※チーム外コミュニケーションが多い場合はサブCLを任命するケースもあり。 |
| オペレーションリード | OL | 障害影響の緩和、解決に向けた実作業のリード役。 配下のDEVメンバー(Operator)への指示も担当。 |
| オンコーラー | OC | アラートを最初に受け取り、状況の把握を行い、迅速にチーム内に連携。 そのまま障害対応メンバーとして、OLに役割を変えて対応することが多い。 |
上記以外にも原因調査や応急対応にあたる要員を適宜アサインしています。
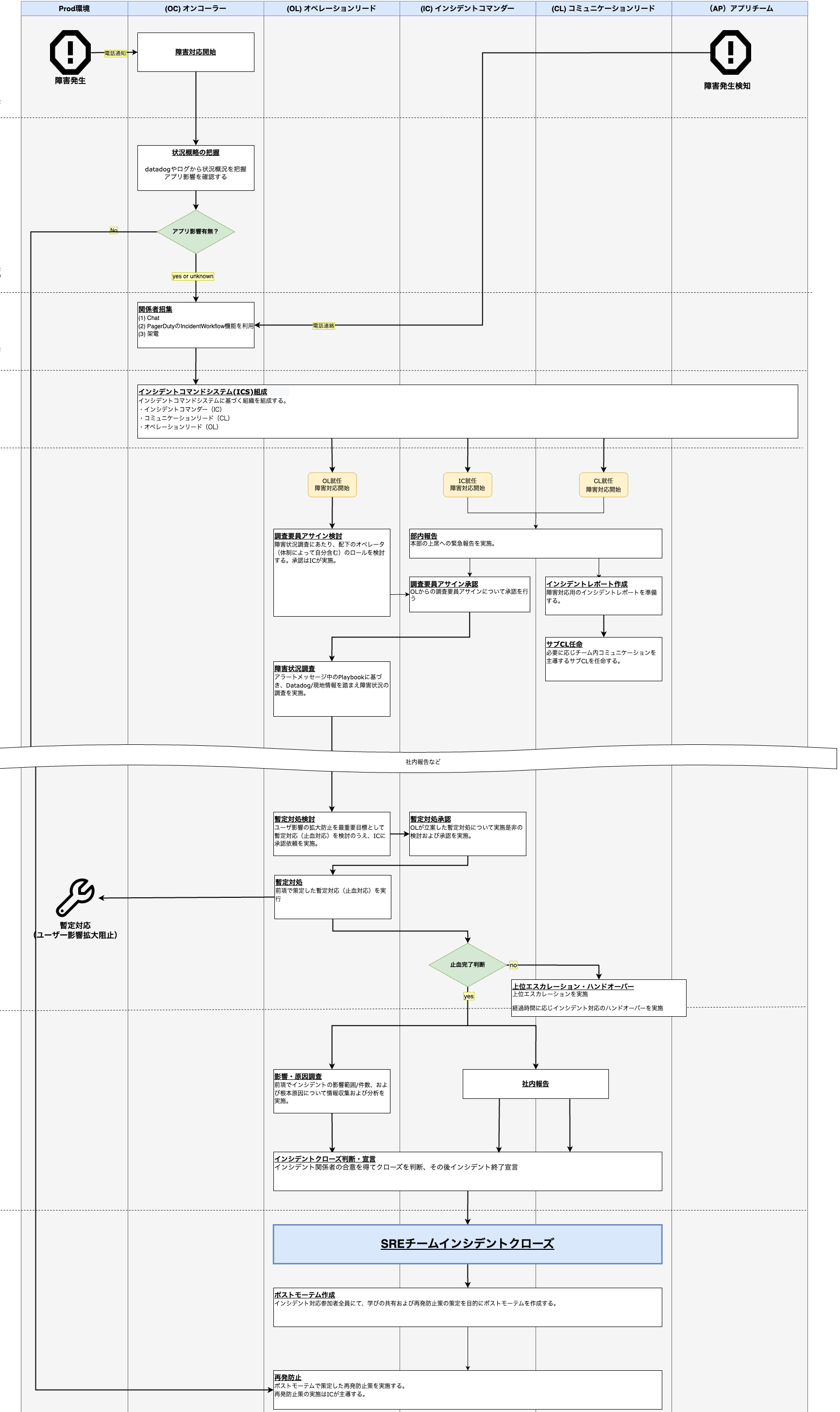
インシデント対応フロー
次に、SREチームが実際にインシデント対応するためのフローをご紹介します。
(社外公開用に簡略化しているため、実際はさらに細かい作業工程があります。)
アラート検知・障害対応開始(OC)
最初にオンコーラーが状況を把握。影響調査を行う。適宜オンコール対応メンバを招集し調査協力を依頼。インシデント宣言
サービスへ影響する可能性がある場合、インシデントを宣言する。インシデントコマンドシステム(ICS)組成
招集されたメンバーから、IC・CL・OLをアサイン。障害影響の調査と緩和作業(OL・Operator)
調査要員をアサインし、まずは影響範囲を最小化・切り分け。その後、復旧作業へ。コミュニケーション(CL)
項番4の対応と並行してインシデントレポートの作成、およびチーム内外、関係各所へのアナウンスと情報共有。復旧確認
復旧作業完了後、サービスが通常どおり稼働しているかチェック。インシデントクローズ
復旧確認を経て、インシデントのクローズを判断し、宣言。ポストモーテム作成
根本原因や再発防止策を整理し、チームにフィードバック。
上記を図に落としたものが以下になります。(実際にこのフローを見て対応にあたっています。)
また、インシデントの調査・対応が終了しても、それで終わりではありません。
最終的にポストモーテムを作成し、
- 根本原因の特定
- 再発防止に向けた具体的アクション
をチーム内で検討・決定し、今後の障害対応力をさらに高めています。
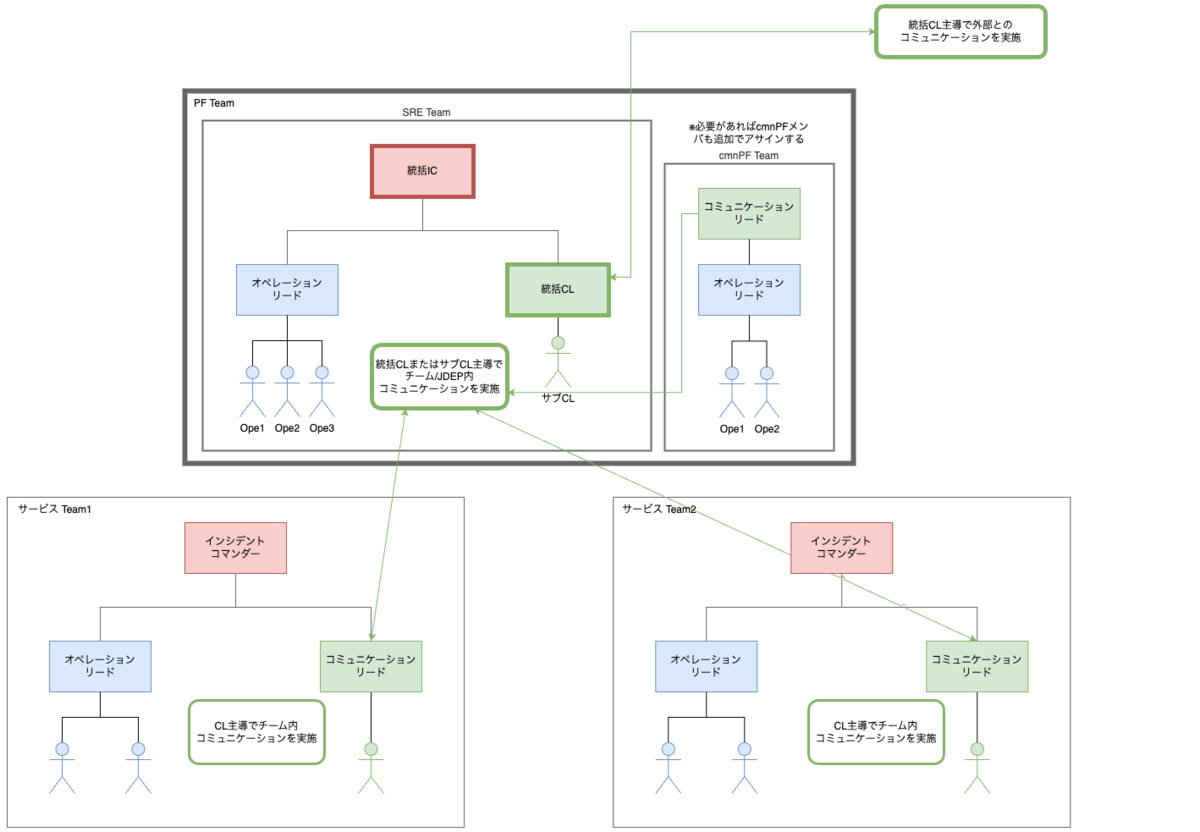
大規模基盤障害時の対応
JDEP内のあらゆるサービスが影響を受けるような基盤障害が発生した場合、すべてのサービスチームに情報を連携し、対応を図る必要があります。
このときはSREチームが「統括インシデント対応チーム」となり、以下のように統括リーダーを配置して全社的にインシデント対応を進めます。
| 役割 | 略記 | 対応内容 |
|---|---|---|
| 統括インシデントコマンダー | 統括IC | JDEP全体の障害対応を統括。 障害対応における意思決定を担当。 |
| 統括コミュニケーションリード | 統括CL | JDEP全体のコミュニケーションを統括。 各アプリチームCLとの連携や、チーム内外への障害報告を担当。 |
また、基盤障害時は必要に応じてcmnPFチームにも協力を要請し、調査にあたります。
※cmnPFチーム:GKEを中心とした、アプリケーションが稼働する各種環境構築や、Google Cloudを主として構成されるプラットフォームの維持管理を担当。
「実際にこんなフロー通りに動けるの?」への疑問
フロー図を見ていると、やることが多くて「本当にこんなにスムーズに対応できるの?」と思うかもしれません。
もちろん、最初から完璧に動けるわけではありません。訓練の積み重ねこそが重要です。
JDEPでは定期的な障害訓練やGameDayを実施し、本番さながらのインシデントを想定して対応の練習を繰り返しています。(Gamedayの紹介記事は こちら から)
これにより、
- 「今は何をすべきか」
- 「次は誰がどんな対応をするのか」
を判断できるようになり、チーム全体のインシデント対応スキルが着実に向上していきます。
おわりに
以上が、JDEP SREチームのインシデントポリシーの概要です。
インシデント対応の考え方や流れは企業やサービスによってさまざまですが、この記事が少しでも皆さんの興味を引くものになれば幸いです。
また、アドベントカレンダー企画における投稿は本記事で最後となります。 今回はたくさんの記事が投稿されましたので、気になる記事があればぜひ読んでみてくださいね。
最後になりますが、JCBでは我々と一緒に働きたいという人材を募集しています。 詳しい募集要項等については採用ページをご覧下さい。 www.saiyo.jcb.co.jp
Merry Christmas!🎄
本文および図表中では、「™」、「®」を明記しておりません。 記載されているロゴ、製品名は各社及び商標権者の登録商標あるいは商標です。