
本稿はJCB Advent Calendar 2023の12月1日の記事です。
PFチームの平松です。
本ブログを執筆するメンバーはJCB Digital Enablement Platform (JDEP)と名付けたプラットフォーム上に、マルチテナント方式で各種アプリをデプロイして運用しています。
前身のビジネス構築の高速化プロジェクトが発足して以来構築を進めたJDEPですが、2023年12月現在2桁を超えるアプリケーションの開発・運用が行われており、 我々PFチームも拡大する組織に合わせてAPLチームが動きやすい環境構築に携わってきました。
各アプリケーションはそれぞれ独自にCritical User Journey (CUJ)およびService Level Indicator (SLI)を設定し、SLIの目標値としてService Level Objective (SLO)を定義してきました。
今回、我々PFチームが提供するサービスについても徐々にではありますがSLOを定義し、SLOで定めたエラーバジェットの残存率に従ってサポート体制を整えるような仕組みを整え始めたので、その取り組みを紹介したいと思います。
Platform SLO Dashboardの一例
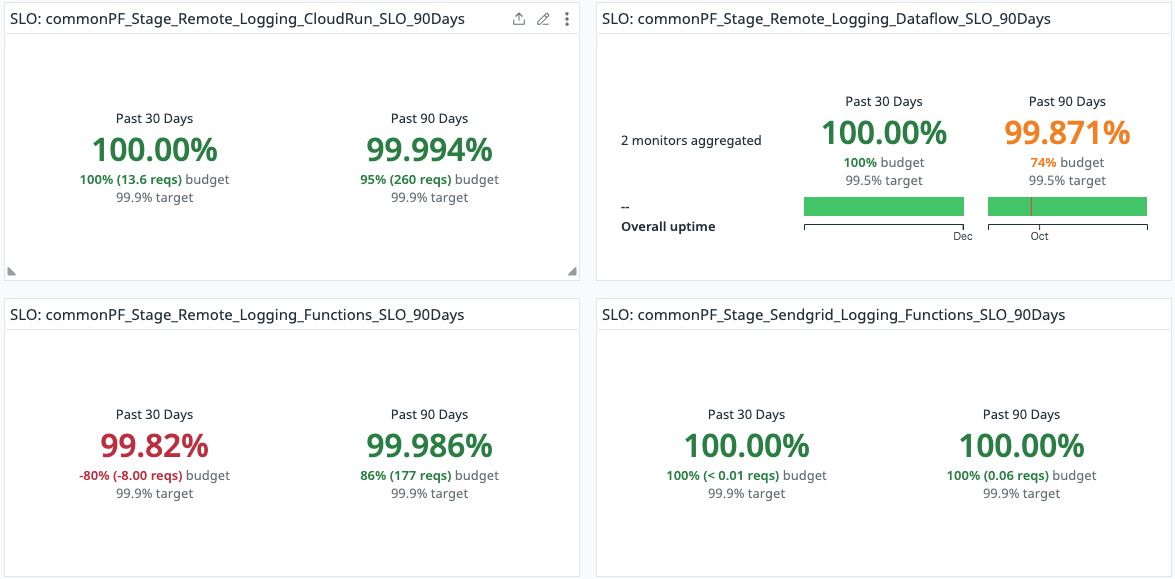
こちらのイメージは、Datadog上で作成したPFチームが適用しているサービスのSLO Dashboardです。過去30日間・90日間のSLOが一目でわかるので、非常に使い勝手の良いものとなっています。
今回は、PFチーム提供機能の中で過去の私の記事で紹介したリモートログ参照機能にフォーカスしていきます。
CUJ, SLIの決定
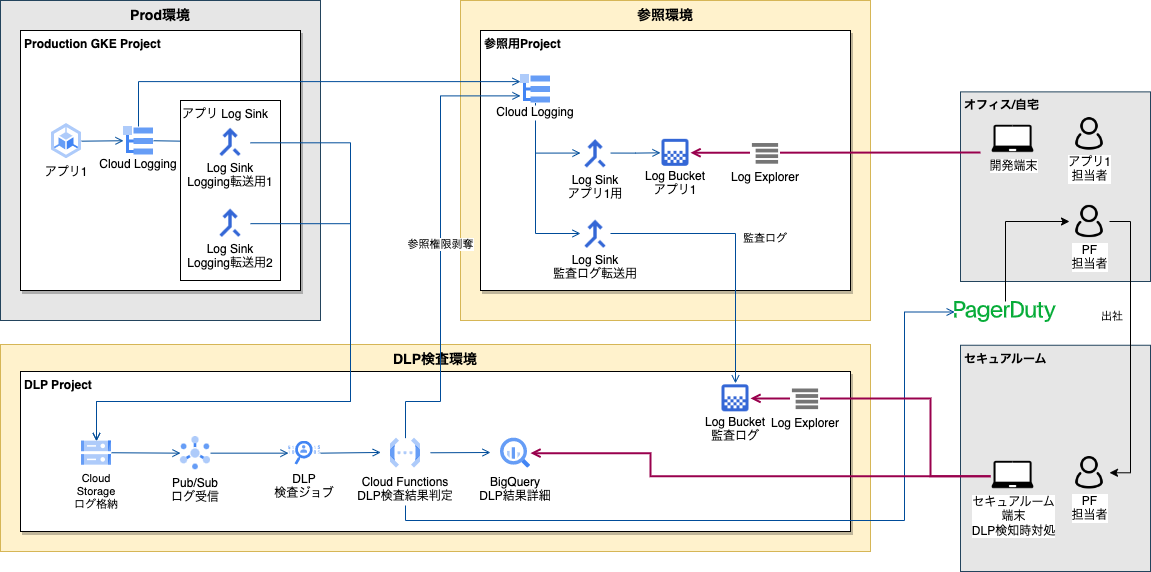
SLOを定めるためのCUJ, SLIについてですが、本機能では以下構成図で示した通り、複数のGCPマネージドサービスを組み合わせて実現しています。 GCF等の各コンポーネントが正しく動作することが必須となることから、以下の通りにまとめました。
- CUJ : APLチームユーザーによるログ参照
- SLI : DLP検査環境内の一連のコンポーネントの稼働率
SLO検討
SLIが決定したことで、SLOの検討に入ります。 本サービスで利用しているGCPマネージドサービスのSLAは2023年11月現在、以下のようになっています。
- Cloud Run : >= 99.95%
- Cloud Functions : >= 99.95%
- Cloud Pub/Sub : >= 99.95%
- BigQuery (Standard Edition) : >= 99.9%
- Cloud Logging : >= 99.95%
- Cloud Storage : >= 99.95%
本機能は運用補助機能であって直接価値を生むものではないため構成要素のSLAを超えた設定は過剰と判断し、 利用サービスを見直すことはしませんでした。 よって、SLOの値は最大でも上記SLAの範囲(99.9%)で設定することとなります。
さらに本機能の構築時から現在までの運用結果から、一旦Datadog上のTarget設定は99.5% (Warningレベルを99.9%)に設定しました。
運用検討
ここまでで冒頭のDashboardの元となる各コンポーネントごとのSLOを定義することができました。 そこで、実際の運用サポート体制についてもSLO中心で考えていきます。
まずは、SLOブレイク時に発報するように、Monitorを設定します。
- エラーバジェットが50%を下回ったらWarning
- エラーバジェットが80%を下回ったらAlert
- エラーバジェットが50%以上に回復したらRecovery
ここでも本機能は運用補助機能であるという整理から、必ずしも即時対応を検討することはないと定義し、検知時の対応は以下の通りとしました。
通知時間帯の定義
- Monitor検知されたのが営業日の場合、即時対応。
- 夜間・休日の場合、翌営業日での対応。
通知受信者 or その他メンバーが気づいた時点でアラート内容を確認し、当該問題事象が継続的 or 一時的に発生したものかを確認する。
- 一時的であった場合
- エラーバジェットの状況を確認し、PFに周知する。
- 継続的であった場合
- 営業日内の場合、解決に向けた体制を構築し、即座にトラブル対応にあたる。
- 営業日外の場合、翌営業日に復旧できるよう体制を構築し、翌営業日にてトラブル対応にあたる。
- 一時的であった場合
運用体制強化とSLO改善施策
上記の通り、今回の機能は比較的クリティカルな機能ではないため、サポート体制の構築については無理のない体制に留めています。
しかし、万が一トラブルが継続してSLOブレイクを起こしてしまった場合は、エラーバジェットが回復するまでは以下の改善策を実行します。
- 夜間・休日の翌営業日体制を即日体制にする
- コンポーネントのロジックを見直す
- 負荷軽減策の実装
- エラー時の復旧時間を可能な限り短くする処理の実装
- 障害復旧プロセスの改善、プレイブックの充実
終わりに
以上、PFチームにおいてAPLチームに提供している機能に関してSLOの策定・運用体制の構築方法・SLOブレイク時の改善策を検討し、運用を開始しています。
まだ始めたばかりで大したエラーも出ていないので順調ですが、今後はエラーが発生した場合に備えた障害訓練を行う等も検討しています。
最後になりますが、JCBでは我々と一緒に働きたいという人材を募集しています。 詳しい募集要項等については採用ページをご覧下さい。
本文および図表中では、「™」、「®」を明記しておりません。 Google Cloud, GCPならびにすべてのGoogleの商標およびロゴはGoogle LLCの商標または登録商標です。 記載されているロゴ、システム名、製品名は各社及び商標権者の登録商標あるいは商標です。